[WIP] Simu Course réaliste + Map + Volant

Re: [WIP] Simu Course réaliste + Map + Volant
ça m'intéresse aussi !!! 
Re: [WIP] Simu Course réaliste + Map + Volant
OK alors je me lance dans une petite explication.
Si vous voulez comparer, il y a une explication de la première version en page 1 du sujet.
Alors, pour commencer, il n'y a rien, juste un gameobject empty avec un script. ^^
en structure j'ai :
Avec ça je peut stocker toutes les donnée dont j'ai besoin.
Je commence par créer 8 vertex, et les edge et triangle correspondant:

Ensuite, pour chacune des edges, je rajoute un point au milieu, je multiplie donc par 4 le nombre de triangle. c'est en fait une simple subdivision genre tesselation ou turboSmooth de 3ds max par exemple. je réalise l'action 5 fois , en ajoutant un peu de smooth et repousse les bords sur un cercle. La subdivision se passe en multithread :

Je cré la forme basique de l'ile en choisissant quelques points que je met en rouge, d'autres en bleu et je propage les couleurs aux voisins :

Cette fois je procède a la subdivision de edge uniquement pour ceux qui ont deux points rouge, et en trouvant les points rouge qui ont un voisin bleu, je détermine une ligne de cote, que j'adouci :

Je réalise encore une fois l'action, en deplaçant la cote vers la terre pour avoir une transition douce entre la densité des point bleu et les rouges :

Encore une fois la même étape mais cette fois je rajoute un calcul des hauteurs, basé sur la distance entre un point et son point de la cote le plus proche ( calcul GPU, voir après) :

Et je subdivise encore une fois, mais cette fois au lieu d'une élévation par rapport a la cote, je calcul un mix de noise via GPU, une petite tambouille qui mix 15 itération de noise avec l'altitude de base pour tenter d'avoir un relief cohérent :

Enfin une dernière itération de subdivision, pour arriver au nombre final de vertex et triangles :

et sans le debug qui affiche les edge :

Pour ce qui est du multithreading des subdivisions, faut éviter les modification de valeurs commune, l'ajout de plusieurs threads à une même liste (d'ailleurs les listes sont trop lente, préférer les array) ou l'incrémentation d'une même valeurs par plusieurs thread. Il me faut donc savoir , pour chaque triangles, le nombre max futur de triangle, idem pour les edge et les points pour redimensionner les array. J'ai donc :
- l'ajout d'un point par edge donc :
- pour chaque Edge, je les coupe en deux donc 2x plus, et dans chaque triangle, 3 nouveaux edge qui relient les trois noux point de chaque edge, et donc :
- et pour chaque triangle, j'en ai 4x plus (un pour chaque sommets + un central) :
Ensuite, encore dans le thread principal, j'ajoute les points au milieu de chaque edge en suivant une condition de couleur ( tous aux premières étapes, puis juste ceux aux point rouge), et pour chaque edge j'assigne l'indice du nouvel edge créé:
C'est ensuite qu’intervient le multi thread vu le nombre de triangles. chaque thread (8) calcul une partie des triangles (1/8). faut donc assigner les thread :
Pour chaque thread lancé, je calcul le premier et le dernier triangle dont il doit s'occuper :
et pour chaque triangle, trois cas possible :
- tout ses points bleu ou un seul point rouge, pas de subdivision
- deux points rouge, une division qui cré deux triangles a la place d'un seul
- trois points rouge , une division qui fait 4 triangle à partir d'un seul.
A ce moment je me retrouve avec des arrays plus long que le nombre reel d'éléments utilisé (vu j'ai compté le nombre max possible), 'ai donc une petite fonction qui, en thread principal, qui retrouve que les éléments utilisé, réarange les array pour supprimer les éléments inutilisé :
Voilà dans les grandes lignes pour le multiThread, maintenant passons au compute shader, ^^ :
Donc c'est sensiblement les même genre de fonction qu'en C#, mais executé par le GPU. L'avantage c'est que du coup on a acces a 1024 unité de calcul (768 pour le shader 4.0) contre 8 pour le multithread.
pour l'utiliser, il faut transmettre les données au GPU via des buffer.
ça peut etre de simple array de int, float ou autre, ou des struct personalisée. en cas de struct personalisée, il faut qu'ils soit déclaré à l'identique dans le compute shader, ordre, nom..
Par exemple dans le script en C# :
faut retrouver dans le compute shader :
Il faut eviter d'envoyer trop de donnée, car c'est le plus long par rapport au temps de calcul, d'ou ce struct avec juste la position et le couleur des vertex (pour éviter d'envoyer des infos qui ne me seront pas utiles comme les points voisins)
Je déclare donc en C# mon nouveau struct et ses valeurs pour le calcul de l'élévation:
et faut créer un buffer qui va stocker, envoyer au GPU et aussi pouvoir les récupérer plus tard :
ensuite il faut savoir combien de donné va traiter chaque thread du GPU :
et on assigne au GPU la donnée :
avec forcément la déclaration de "Point" dans le compute shader :
ensuite il faut retrouver dans le compute shader le "Kernel" qui est en fait l'index de la fonction que l'ont va utiliser. on peut donc avoir un seul compute shader, avec plusieurs fonction donc de kernel, il suffit de trouver le bon :
On déclare en C# :
qui va retrouver dans le compute shader :
ensuite en C# il suffit de lancer l'execution du GPU :
et enfin récupérer les données modifiée par le GPU, et les libérer :
le code complet donnerai :
En C#:
et dans le compute shader :
bon voila, c'est peut etre pas tres clair, j'en ai surement oublié. Je me suis basé sur cette page qui explique certainement bien mieux que moi ^^
Apres si vous avezz des questions, je peux tenter d'y répondre
en attendant je laisse un petit lien vers le standalone si vous voulez tester.
Et le script complet et le compute shader complet :
Si vous voulez comparer, il y a une explication de la première version en page 1 du sujet.
Alors, pour commencer, il n'y a rien, juste un gameobject empty avec un script. ^^
en structure j'ai :
Code : Tout sélectionner
struct POINT
{
public Vector3 pos; // position du vertex
public int[] PointNext; // array des vertex directement connectés par un edge
public int PNC; // nombre de vertexconnecté, pour se passer des listes moins rapides
public int Color; // couleur du vertex
}
struct EDGE
{
public int P1; // premier vertexx de l'edge
public int P2; // deuxieme vertex de l'edge
public int Enew; // lors d'une subdivision, le nouvel edge créé
}
struct TRI
{
public int P1; // vertex 1 du triangle
public int P2; // vertex 2 du triangle
public int P3; // vertex 3 du triangle
public int E1; // edge 1 du triangle
public int E2; // edge 2 du triangle
public int E3; // edge 3 du triangle
}Je commence par créer 8 vertex, et les edge et triangle correspondant:
Ensuite, pour chacune des edges, je rajoute un point au milieu, je multiplie donc par 4 le nombre de triangle. c'est en fait une simple subdivision genre tesselation ou turboSmooth de 3ds max par exemple. je réalise l'action 5 fois , en ajoutant un peu de smooth et repousse les bords sur un cercle. La subdivision se passe en multithread :
Je cré la forme basique de l'ile en choisissant quelques points que je met en rouge, d'autres en bleu et je propage les couleurs aux voisins :
Cette fois je procède a la subdivision de edge uniquement pour ceux qui ont deux points rouge, et en trouvant les points rouge qui ont un voisin bleu, je détermine une ligne de cote, que j'adouci :
Je réalise encore une fois l'action, en deplaçant la cote vers la terre pour avoir une transition douce entre la densité des point bleu et les rouges :
Encore une fois la même étape mais cette fois je rajoute un calcul des hauteurs, basé sur la distance entre un point et son point de la cote le plus proche ( calcul GPU, voir après) :
Et je subdivise encore une fois, mais cette fois au lieu d'une élévation par rapport a la cote, je calcul un mix de noise via GPU, une petite tambouille qui mix 15 itération de noise avec l'altitude de base pour tenter d'avoir un relief cohérent :
Enfin une dernière itération de subdivision, pour arriver au nombre final de vertex et triangles :
et sans le debug qui affiche les edge :
Pour ce qui est du multithreading des subdivisions, faut éviter les modification de valeurs commune, l'ajout de plusieurs threads à une même liste (d'ailleurs les listes sont trop lente, préférer les array) ou l'incrémentation d'une même valeurs par plusieurs thread. Il me faut donc savoir , pour chaque triangles, le nombre max futur de triangle, idem pour les edge et les points pour redimensionner les array. J'ai donc :
- l'ajout d'un point par edge donc :
Code : Tout sélectionner
Array.Resize (ref Point, Point.Length + Edge.Length);Code : Tout sélectionner
Array.Resize (ref Edge, Edge.Length * 2 + Tri.Length * 3);Code : Tout sélectionner
Array.Resize (ref Tri, Tri.Length * 4);Code : Tout sélectionner
for (int e = 0; e < EdgeCount; e++) {
p1 = Edge [e].P1;
p2 = Edge [e].P2;
if (p1 != p2) {
Moyenne = Point [p1].Color + Point [p2].Color;
if (Moyenne > 1) {
Point [PointCount + e].pos = (Point [p1].pos + Point [p2].pos) * 0.5f;
Point [PointCount + e].Color = Mathf.Max (Point [p1].Color, Point [p2].Color);
Point [PointCount + e].PointNext = new int[7];
Edge [EdgeCount + e].P1 = p2;
Edge [EdgeCount + e].P2 = PointCount + e;
Edge [e].P2 = PointCount + e;
Edge [e].Enew = EdgeCount + e;
} else {
Edge [e].Enew = -1;
}
}
}Code : Tout sélectionner
for (int k = 0; k < core; k++) { // core = nombre de cœurs dispo du processeur, ici 8
int K = k;
tache [K] = new Thread (ThreadTri);
tache [K].Start (K);
}
for (int i = 0; i < core; i++) {
tache [i].Join ();
}Code : Tout sélectionner
int y = Convert.ToInt32 (K);
int count = (TriCount / core); // TriCount = Tri.length
int start = y * count;
int end = (y + 1) * count;
if (y == (core - 1)) {
end = TriCount;
}- tout ses points bleu ou un seul point rouge, pas de subdivision
- deux points rouge, une division qui cré deux triangles a la place d'un seul
- trois points rouge , une division qui fait 4 triangle à partir d'un seul.
Code : Tout sélectionner
for (int t = start; t < end; t++) { // on s'occupe juste des triangles utilisé par le thread
if ((Tri [t].P1 + Tri [t].P2) != 0) {
offsetE = EdgeCount * 2 + t * 3; // pour chaque edge on a deja crée un autre en ajoutnt les points,
//ensuite pour chaque triangle au mieux on ajout trois edge.
// OffsetE sers pour chaque triangle à n'assigner des nouveaux edges unique
// sans que plusieurs triangles assignent deux fois le même edge.
// on liste les edge du triangles et les edge nouveau de chaque edge s'il y en a
triE [0] = Tri [t].E1;
triE [1] = Edge [triE [0]].Enew;
triE [2] = Tri [t].E2;
triE [3] = Edge [triE [2]].Enew;
triE [4] = Tri [t].E3;
triE [5] = Edge [triE [4]].Enew;
// on stock les trois points du triangle
triP [0] = Tri [t].P1;
triP [1] = Tri [t].P2;
triP [2] = Tri [t].P3;
// calcul de la couleur moyenne des points du triangle
Moyenne = Point [triP [0]].Color + Point [triP [1]].Color + Point [triP [2]].Color;
// si tout les points du triangle sont rouge (ou blanc pour les premières étapes) :
if (Moyenne > 2) {
// pour chacun des points du triangles, il va y avoir un nouveau triangle
for (int p = 0; p < triP.Length; p++) {
pointCount = 0;
edgeCount = 0;
for (int e = 0; e < triE.Length; e++) {
Te = triE [e];
if (Edge [Te].P1 == triP [p] && pointCount < 2) {
point [pointCount] = Edge [Te].P2;
edge [edgeCount] = Te;
pointCount += 1;
edgeCount += 1;
}
if (Edge [Te].P2 == triP [p] && pointCount < 2) {
point [pointCount] = Edge [Te].P1;
edge [edgeCount] = Te;
pointCount += 1;
edgeCount += 1;
}
}
// idem que pour OffsetE, offsetT pour que chaque tri ne modifie jamais deux fois le meme triangle
offsetT = TriCount + t * 3 + p;
Edge [offsetE + p].P1 = point [0];
Edge [offsetE + p].P2 = point [1];
Tri [offsetT] = new TRI (triP [p], point [0], point [1], edge [0], edge [1], offsetE + p);
}
Tri [t] = new TRI (Edge [triE [0]].P2, Edge [triE [2]].P2, Edge [triE [4]].P2, offsetE, offsetE + 1, offsetE + 2);
// si deux points blancs (les points des cotes on été passé a blanc):
} else if (Moyenne == 2) {
int C = 0;
for (int p = 0; p < triP.Length; p++) {
// pour chacun des points, on va rajouter juste un triangle pour les somet blanc
if (Point [triP [p]].Color == White) {
pointCount = 0;
edgeCount = 0;
for (int e = 0; e < triE.Length; e++) {
Te = triE [e];
if (Te != -1) {
if (Edge [Te].P1 == triP [p] && pointCount < 2) {
point [pointCount] = Edge [Te].P2;
edge [edgeCount] = Te;
pointCount += 1;
edgeCount += 1;
} else if (Edge [Te].P2 == triP [p] && pointCount < 2) {
point [pointCount] = Edge [Te].P1;
edge [edgeCount] = Te;
pointCount += 1;
edgeCount += 1;
}
}
}
C += 1;
if (C == 1) {
offsetT = TriCount + t * 3 + p;
Tri [offsetT] = new TRI (triP [p], point [0], point [1], edge [0], edge [1], offsetE);
} else {
Tri [t] = new TRI (triP [p], point [0], point [1], edge [0], edge [1], offsetE);
}
}
}
Edge [offsetE].P1 = point [0];
Edge [offsetE].P2 = point [1];
}
}
}Code : Tout sélectionner
void reduce ()
{
int[] PointTemp = new int[Point.Length];
int[] EdgeTemp = new int[Edge.Length];
int Pcount = 0;
int Ecount = 0;
int Tcount = 0;
for (int i = 0; i < Point.Length; i++) {
if (Point [i].PNC != 0) {
PointTemp [i] = Pcount;
Point [Pcount] = Point [i];
Pcount += 1;
}
}
for (int i = 0; i < CoteCount; i++) {
COTE [i] = PointTemp [COTE [i]];
}
for (int i = 0; i < Edge.Length; i++) {
if (Edge [i].P1 != Edge [i].P2) {
EdgeTemp [i] = Ecount;
Edge [Ecount].P1 = PointTemp [Edge [i].P1];
Edge [Ecount].P2 = PointTemp [Edge [i].P2];
if (Edge [i].Enew != -1) {
Edge [Ecount].Enew = EdgeTemp [Edge [i].Enew];
}
Ecount += 1;
}
}
for (int i = 0; i < Tri.Length; i++) {
if ((Tri [i].P1 + Tri [i].P2) != 0) {
Tri [Tcount].P1 = PointTemp [Tri [i].P1];
Tri [Tcount].P2 = PointTemp [Tri [i].P2];
Tri [Tcount].P3 = PointTemp [Tri [i].P3];
Tri [Tcount].E1 = EdgeTemp [Tri [i].E1];
Tri [Tcount].E2 = EdgeTemp [Tri [i].E2];
Tri [Tcount].E3 = EdgeTemp [Tri [i].E3];
Tcount += 1;
}
}
Array.Resize (ref Point, Pcount);
Array.Resize (ref Edge, Ecount);
Array.Resize (ref Tri, Tcount);
}Donc c'est sensiblement les même genre de fonction qu'en C#, mais executé par le GPU. L'avantage c'est que du coup on a acces a 1024 unité de calcul (768 pour le shader 4.0) contre 8 pour le multithread.
pour l'utiliser, il faut transmettre les données au GPU via des buffer.
ça peut etre de simple array de int, float ou autre, ou des struct personalisée. en cas de struct personalisée, il faut qu'ils soit déclaré à l'identique dans le compute shader, ordre, nom..
Par exemple dans le script en C# :
Code : Tout sélectionner
private struct POINT1
{
public Vector3 pos;
public int Color;
public POINT1 (Vector3 pos, int Color)
{
this.pos = pos;
this.Color = Color;
}
}Code : Tout sélectionner
struct POINT1
{
half3 pos;
uint Color;
};Je déclare donc en C# mon nouveau struct et ses valeurs pour le calcul de l'élévation:
Code : Tout sélectionner
POINT1[] P = new POINT1[PointCount];
for (int i = 0; i < PointCount; i++) {
P [i].pos = Point [i].pos;
P [i].Color = Point [i].Color;
}Code : Tout sélectionner
// PointCount est le nombre d'éléments que va contenir l'array, ou plutôt le buffer
// 16 est le nombre de bit, avec 4 bit par donnée, donc 4x3 pour le vector3 et 4 pour le int
ComputeBuffer VertexBuffer = new ComputeBuffer (PointCount, 16);
VertexBuffer.SetData (P);Code : Tout sélectionner
int NbThreadX = PointCount / 1024 + 1;Code : Tout sélectionner
MyCompute.SetBuffer (IndexKernel, "Point", VertexBuffer);
// avec Mycompute le compute shader déclaré en C# par "public ComputeShader MyCompute;"
// "Point" le nom de la variable dans le compute shader ou assigner les valeurs
// VertexBuffer a assigner a "Point" du compute shader Code : Tout sélectionner
RWStructuredBuffer<POINT1> Point;On déclare en C# :
Code : Tout sélectionner
int IndexKernel = MyCompute.FindKernel ("Elevation");Code : Tout sélectionner
#pragma kernel Elevation // déclaration du Kernel
[numthreads(1024,1,1)] //
void Elevation (uint3 id : SV_DispatchThreadID)// la fonction correspondant au kernel "Elevation"
{
// ici tout le code qui devra être utilisé
}Code : Tout sélectionner
MyCompute.Dispatch (IndexKernel, NbThreadX, 1, 1);Code : Tout sélectionner
VertexBuffer.GetData (P); // on recupere le données du buffer "VertexBuffer" qu'on defini à la place de "P"
VertexBuffer.Release ();En C#:
Code : Tout sélectionner
public class Map : MonoBehaviour
{
// déclaration d'un struct
private struct POINT1
{
public Vector3 pos;
public int Color;
public POINT1 (Vector3 pos, int Color)
{
this.pos = pos;
this.Color = Color;
}
}
déclaration du compute shader, qu'il faudra indiquer dans l'inspecteur
public ComputeShader MyCompute;
// une fonction
void Elevation ()
{
// on assigne des valeurs
POINT1[] P = new POINT1[PointCount];
for (int i = 0; i < PointCount; i++) {
P [i].pos = Point [i].pos;
P [i].Color = Point [i].Color;
}
// on defini quel kernel du compute shader on va utiliser
int IndexKernel = MyCompute.FindKernel ("Elevation");
// on crée un buffer avec un nombre d'élément et de bit
ComputeBuffer VertexBuffer = new ComputeBuffer (PointCount, 16);
// on assigne une donnée au buffer
VertexBuffer.SetData (P);
// on calcul le nombre d'élément que va taiter chaque thread du GPU
int NbThreadX = PointCount / 1024 + 1;
// on assigne au GPU le buffer
MyCompute.SetBuffer (IndexKernel, "Point", VertexBuffer);
// on dispatch les données au kernel, en fonction du nombre de thread a utiliser
MyCompute.Dispatch (IndexKernel, NbThreadX, 1, 1);
// on recupère les donnée du GPU pour les retrouver dans le CPU
VertexBuffer.GetData (P);
// on libere les données alouées au GPU
VertexBuffer.Release ();
}
}Code : Tout sélectionner
// déclaration du kernel
#pragma kernel Elevation
// declaration du struct
struct POINT1
{
half3 pos;
uint Color;
};
// déclaration de la variable
RWStructuredBuffer<POINT1> Point;
// definition du kernel et le nombre de thread utilisée
[numthreads(1024,1,1)]
void Elevation (uint3 id : SV_DispatchThreadID)
{
// exemple : on redefini la position de chaque point par un vecteur3 zero
// id.x est l'index du point
Point[id.x].pos = half3(0,0,0)
}
Apres si vous avezz des questions, je peux tenter d'y répondre
en attendant je laisse un petit lien vers le standalone si vous voulez tester.
Et le script complet et le compute shader complet :
► Afficher le texte
______________________________________________________________
\_______________________ Impossible is nothing _______________________/
Re: [WIP] Simu Course réaliste + Map + Volant
Juste pour rajouter, les screen précédents sont issu d'unity en mode play, d’où les statistiques moyenne, en standalone ça donne ça (Pc de 6ans avec i7 3820 4 core 3.6GHz, Nvidia 670 GTX, 16Go Ram) :




______________________________________________________________
\_______________________ Impossible is nothing _______________________/
Re: [WIP] Simu Course réaliste + Map + Volant
Magnifique ! Merci beaucoup !

Re: [WIP] Simu Course réaliste + Map + Volant
Super et merci pour cet exposé très complet. Plus qu'a intégrer cela à tête reposée.


Pas d'aide par MP, le forum est là pour ça.
En cas de doute sur les bonnes pratiques à adopter sur le forum, consulter la Charte et sa FAQ

Re: [WIP] Simu Course réaliste + Map + Volant
très impressionnant, et le résultat est magnifique.
Bravo et merci à toi, c'est super instructif.
tout ça pour une course de voitures, quand même
Bravo et merci à toi, c'est super instructif.
tout ça pour une course de voitures, quand même
Re: [WIP] Simu Course réaliste + Map + Volant
Merci pour vos retours 
Mais surtout ça me permet de découvrir et d'apprendre plein de choses.
Et puis aussi le fait de modéliser toute une map pour y jouer au moins moi même, bah au final je la connaitrait plus que par cœur et perdrait un peu d’intérêt, et puis c’est long de modéliser tout ça ^^.
Aussi, bien que pour quiconque ça peu être sympa de connaitre les routes/circuits pour jouer, dès le départ j'ai eu l'envie d'avoir quelque chose de procédural pour avoir en permanence un coté découverte.
Alors bon, suis pas prêt de pouvoir conduire sur mes iles, mais déjà bien content de l'avancé et de mes progrès : passer de 20 secondes pour générer 1M de tri contre moins d'une seconde pour en générer presque 4M.
Hé hé à la base oui c'est juste pour un jeu de voiture.
Mais surtout ça me permet de découvrir et d'apprendre plein de choses.
Et puis aussi le fait de modéliser toute une map pour y jouer au moins moi même, bah au final je la connaitrait plus que par cœur et perdrait un peu d’intérêt, et puis c’est long de modéliser tout ça ^^.
Aussi, bien que pour quiconque ça peu être sympa de connaitre les routes/circuits pour jouer, dès le départ j'ai eu l'envie d'avoir quelque chose de procédural pour avoir en permanence un coté découverte.
Alors bon, suis pas prêt de pouvoir conduire sur mes iles, mais déjà bien content de l'avancé et de mes progrès : passer de 20 secondes pour générer 1M de tri contre moins d'une seconde pour en générer presque 4M.
______________________________________________________________
\_______________________ Impossible is nothing _______________________/

Re: [WIP] Simu Course réaliste + Map + Volant
Beau travail!
L'ensemble de ton post est vraiment très intéressant. le rendu est vraiment impeccable! Merci de partager ton travail, Il est fort probable que dans un projet futur je vienne souvent par ici y puiser des trucs
L'ensemble de ton post est vraiment très intéressant. le rendu est vraiment impeccable! Merci de partager ton travail, Il est fort probable que dans un projet futur je vienne souvent par ici y puiser des trucs
On s'fait un petit Canvas pour l'apéro?
Pour tester:http://www.starsheepstudio.com
Notre page:https://www.facebook.com/starsheepstudio
Pour tester:http://www.starsheepstudio.com
Notre page:https://www.facebook.com/starsheepstudio
Re: [WIP] Simu Course réaliste + Map + Volant
Merci, et avec plaisir si ça peut te servir un jour.
Juste par curiosité certains ont-ils essayé le standalone ? Pour avoir un retour des temps de génération suivant les machines..
Juste par curiosité certains ont-ils essayé le standalone ? Pour avoir un retour des temps de génération suivant les machines..
______________________________________________________________
\_______________________ Impossible is nothing _______________________/
Re: [WIP] Simu Course réaliste + Map + Volant
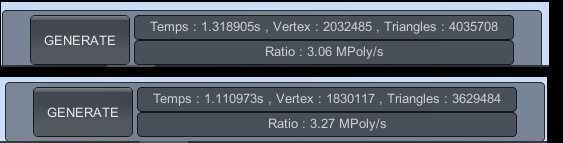
dans mon cas, deux exemples (sur un vieux i7-2600 à 3.40 Ghz et une GTX960) :
Pas d'aide par MP, le forum est là pour ça.
En cas de doute sur les bonnes pratiques à adopter sur le forum, consulter la Charte et sa FAQ